微服务应用优雅上下线
背景
微盟业务线 应用均上k8s,容器化部署, 少量服务VM部署
服务发布窗口均集中在流量较少的夜间
web 层没有统一的 api gateway , 部分业务的api gateway 使用比较粗暴,直接regist 到 traefik
dubbo 使用版本参差不齐 (2.5.x~2.6.x+) 附表链接
需求概述
为支持灰度发布 蓝绿发布等 发布场景.
在一定应用标准化场景下,RPC 框架dubbo, 中间件服务需要支撑应用优雅发布能力,上线下线,做到业务无损,有计划而平滑退出.
名称含义
dubbo 版本现状
2.7.x 和 2.6.x 是目前官方推荐使用的版本,其中 2.7.x 是捐献给 Apache 的版本,具备了很多新的特性,目前最新的 release 版本是 2.7.4,处于生产基本可用的状态;2.6.x 处于维护态,主要以 bugfix 为主,但经过了很多公司线上环境的验证,所以求稳的话,可以使用 2.6.x 分支最新的版本。至于 2.5.x,社区已经放弃了维护,并且 2.5.x 存在一定数量的 bug
dubbo版本总结
https://github.com/apache/dubbo/issues/5669
kill -9
kill -9 pid 可以理解为操作系统从内核级别强行杀死某个进程
kill -15
kill -15 pid 则可以理解为发送一个通知,告知应用主动关闭
停机场景
服务发布(滚动发布) 缩容 重启pod 等
故障转移 failover
即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作
dubbo 版本总结升级建议

SpringBoot & Spring 使用统计
| jar_name | jar_version | count |
|---|---|---|
| spring-boot | 1.5.9.RELEASE | 127 |
| spring-boot | 2.1.3.RELEASE | 92 |
| spring-boot | 1.5.15.RELEASE | 66 |
| spring-boot | 1.5.20.RELEASE | 54 |
| spring-boot | 2.0.0.RELEASE | 35 |
| spring-boot | 1.5.22.RELEASE | 28 |
| spring-boot | 2.0.5.RELEASE | 24 |
| spring-boot | 1.5.19.RELEASE | 23 |
| spring-boot | 1.3.5.RELEASE | 18 |
| spring-boot | 1.5.6.RELEASE | 17 |
| spring-boot | 2.2.2.RELEASE | 17 |
| spring-boot | 2.1.6.RELEASE | 16 |
| spring-boot | 1.5.14.RELEASE | 13 |
| spring-boot | 2.3.4.RELEASE | 13 |
| spring-boot | 1.3.8.RELEASE | 13 |
| spring-boot | 2.3.0.RELEASE | 12 |
| spring-boot | 2.2.6.RELEASE | 12 |
| spring-boot | 1.5.4.RELEASE | 11 |
| spring-boot | 2.3.2.RELEASE | 9 |
| spring-boot | 2.0.3.RELEASE | 8 |
| spring-boot | 2.1.1.RELEASE | 7 |
| spring-boot | 2.1.5.RELEASE | 7 |
| spring-boot | 2.1.2.RELEASE | 6 |
| spring-boot | 1.5.21.RELEASE | 5 |
| spring-boot | 2.1.9.RELEASE | 5 |
| spring-boot | 2.0.2.RELEASE | 4 |
| spring-boot | 1.4.3.RELEASE | 4 |
| spring-boot | 1.5.10.RELEASE | 4 |
| spring-boot | 2.3.3.RELEASE | 3 |
| spring-boot | 2.1.7.RELEASE | 3 |
| spring-boot | 1.4.2.RELEASE | 3 |
| spring-boot | 2.0.1.RELEASE | 3 |
| spring-boot | 2.3.1.RELEASE | 2 |
| spring-boot | 1.5.16.RELEASE | 2 |
| spring-boot | 2.0.6.RELEASE | 2 |
| spring-boot | 1.5.18.RELEASE | 2 |
| spring-boot | 2.2.5.RELEASE | 2 |
| spring-boot | 1.5.13.RELEASE | 1 |
| spring-boot | 2.1.0.RELEASE | 1 |
| spring-boot | 1.5.3.RELEASE | 1 |
| spring-boot | 1.5.7.RELEASE | 1 |
| spring-boot | 2.2.4.RELEASE | 1 |
| spring-boot | 1.5.1.RELEASE | 1 |
| jar_name | jar_version | count |
|---|---|---|
| spring-core | 4.3.18.RELEASE | 154 |
| spring-core | 4.3.13.RELEASE | 134 |
| spring-core | 3.2.9.RELEASE | 95 |
| spring-core | 5.1.5.RELEASE | 92 |
| spring-core | 4.3.10.RELEASE | 57 |
| spring-core | 4.3.23.RELEASE | 55 |
| spring-core | 4.3.20.RELEASE | 34 |
| spring-core | 4.3.25.RELEASE | 30 |
| spring-core | 5.0.9.RELEASE | 24 |
| spring-core | 4.3.22.RELEASE | 23 |
| spring-core | 4.3.9.RELEASE | 20 |
| spring-core | 4.2.6.RELEASE | 18 |
| spring-core | 4.2.1.RELEASE | 15 |
| spring-core | 4.2.8.RELEASE | 14 |
| spring-core | 5.1.8.RELEASE | 13 |
| spring-core | 5.2.9.RELEASE | 13 |
| spring-core | 5.2.2.RELEASE | 12 |
| spring-core | 5.2.5.RELEASE | 12 |
| spring-core | 5.2.6.RELEASE | 12 |
| spring-core | 5.2.8.RELEASE | 12 |
| spring-core | 5.0.7.RELEASE | 8 |
| spring-core | 5.1.7.RELEASE | 7 |
| spring-core | 5.1.3.RELEASE | 7 |
| spring-core | 4.3.24.RELEASE | 5 |
| spring-core | 5.0.6.RELEASE | 4 |
| spring-core | 4.1.6.RELEASE | 4 |
| spring-core | 5.1.10.RELEASE | 4 |
| spring-core | 5.1.4.RELEASE | 4 |
| spring-core | 4.3.4.RELEASE | 3 |
| spring-core | 4.3.5.RELEASE | 3 |
| spring-core | 5.1.9.RELEASE | 3 |
| spring-core | 4.3.14.RELEASE | 3 |
| spring-core | 4.2.7.RELEASE | 2 |
| spring-core | 4.3.16.RELEASE | 2 |
| spring-core | 5.0.10.RELEASE | 2 |
| spring-core | 5.2.4.RELEASE | 2 |
| spring-core | 4.3.17.RELEASE | 2 |
| spring-core | 5.0.4.RELEASE | 2 |
| spring-core | 4.3.19.RELEASE | 2 |
| spring-core | 5.2.7.RELEASE | 2 |
| spring-core | 4.3.21.RELEASE | 2 |
| spring-core | 4.2.9.RELEASE | 1 |
| spring-core | 4.3.6.RELEASE | 1 |
| spring-core | 4.3.7.RELEASE | 1 |
| spring-core | 4.3.8.RELEASE | 1 |
| spring-core | 5.2.3.RELEASE | 1 |
| spring-core | 5.0.5.RELEASE | 1 |
| spring-core | 3.2.16.RELEASE | 1 |
| spring-core | 5.1.2.RELEASE | 1 |
| spring-core | 4.2.5.RELEASE | 1 |
版本使用情况
spring boot 6
spring 4
WEB 应用的启动停止过程
web 应用的启动过程

应用的加载是漫长的,在加载过程,服务是不可预期的;如过早地打开 Socket 监听,则客户端可能感受到漫长的等待;如果数据库、消息队列、REDIS 客户端未完成初始化,则服务可能因缺少关键的底层服务而异常。
所以在应用准备完成后,才接入服务,即做到优雅上线。当然应用上线后,也可能因如数据库断连等情况引起服务不可用;或是准备完成了,但在上线前又发生数据库断连,导致服务异常。为了简化问题,后面两种情况作为一个应用自愈的问题来看待。
web 应用的停止过程

所以关闭服务接入(转移服务接入),完成正在处理的服务,清理自身占用的资源后退出即做到优雅下线
优雅停机的意义
- 操作系统层面,提供了 kill -9 (SIGKILL)和 kill -15(SIGTERM) 两种停机策略
- 语言层面,Java 应用有 JVM shutdown hook 这样的概念
- 框架层面,Spring Boot 提供了 actuator 的下线 endpoint,提供了 ContextClosedEvent 事件
- 容器层面,Docker :当执行 docker stop 命令时,容器内的进程会收到 SIGTERM 信号,那么 Docker Daemon 会在 10s 后,发出 SIGKILL 信号;K8S 在管理容器生命周期阶段中提供了 prestop 钩子方法
- 应用架构层面,不同架构存在不同的部署方案。单体式应用中,一般依靠 nginx 这样的 负载均衡组件进行手动切流,逐步部署集群;微服务架构中,各个节点之间有复杂的调用关系,上述这种方案就显得不可靠了,需要有自动化的机制。
优雅停机的意义:应用的重启、停机等操作,不影响业务的连续性。
微服务优雅停机原则
阶段
引流 → 挡板 → 等待停机
原则 :
- 所有微服务应用都应该支持优雅停机 (rpc mq job dq…)
- 优先注销注册中心注册的服务实例 (zk)
- 待停机的服务应用的接入点标记拒绝服务
- 上游服务支持故障转移因优雅停机而拒绝的服务 (failover)
- 根据具体业务也提供适当的停机接口 (qos)
实现大致路径

接收信号:停止信号可能从进程内部触发(比如 Crash 场景),如果自退出的话基本上无法保证优雅下线;所以能保证优雅下线的前提就是需要正确处理来自进程外部的信号;
停止流量接收:由于在停止之前,我们会有一些正在处理的请求,贸然退出会对这些请求产生损耗。但是在这段时间之内我们绝不能再接收新的业务请求,如果这是一个后台任务型(消息消费型或任务调度型)的程序,也要停止接收新的消息和任务。对于一个普通的 WEB 场景,这一块不同的场景实现的方式也会不一样
- 销毁资源:常见的是一些系统资源,也包括一些缓存、锁的清理、同时也包括线程池、关闭阻塞中的的 IO 操作,等到我们这些服务器资源销毁之后,就可以通知主线程退出。
优雅停机-应用服务

优雅停机-服务网关

核心流程
服务下线

服务上线

java项目下线场景
1 增加一个实现了 DisposableBean 接口的类
1 |
|
2 增加 JVM 关闭时的钩子
1 |
|
测试步骤
- 执行
java -jar test-shutdown-1.0.jar将应用运行起来 - 测试
kill -9 pid,kill -15 pid,ctrl + c后输出日志内容
测试结果
kill -15 pid & ctrl + c,效果一样,输出结果如下
1 | 2018-01-14 16:55:32.424 INFO 8762 --- [Thread-3] ationConfigEmbeddedWebApplicationContext : Closing org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@2cdf8d8a: startup date [Sun Jan 14 16:55:24 UTC 2018]; root of context hierarchy |
kill -9 pid,没有输出任何应用日志
1 | [1] 8802 killed java -jar test-shutdown-1.0.jar |
可以发现,kill -9 pid 是给应用杀了个措手不及,没有留给应用任何反应的机会。而反观 kill -15 pid,则比较优雅,先是由 AnnotationConfigEmbeddedWebApplicationContext (一个 ApplicationContext 的实现类)收到了通知,紧接着执行了测试代码中的 Shutdown Hook,最后执行了 DisposableBean#destory() 方法。孰优孰劣,立判高下
java 项目应用类型
Non-Spring
Spring Boot
Spring + ContextClosedEvent
普通java 项目的停机:
1 | public class Main{ |
首先JVM本身是支持通过shutdownHook的方式优雅停机的。
1 | Runtime.getRuntime().addShutdownHook(new Thread() { |
此方式支持在以下几种场景优雅停机:
1.程序正常退出
2.使用System.exit()
3.终端使用Ctrl+C
4.使用Kill pid干掉进程
spring 项目
在 Spring 中,我们可以使用至少三种方式来注册容器关闭时一些收尾工作
1 使用 DisposableBean 接口
1 | public class TestDisposableBean implements DisposableBean { |
2使用 @PreDestroy 注解
1 | public class TestPreDestroy { |
3 使用 ApplicationListener 监听 ContextClosedEvent
1 | applicationContext.addApplicationListener(new ApplicationListener<ApplicationEvent>() { |
但需要注意的是,在使用 SpringBoot 内嵌 Tomcat 容器时,容器关闭钩子是自动被注册,但使用纯粹的 Spring 框架或者外部 Tomcat 容器,需要显式的调用 context.registerShutdownHook(); 接口进行注册
1 | ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring/beans.xml"); |
registerShutdownHook() 实现
1 | public abstract class AbstractApplicationContext extends DefaultResourceLoader |
Spring Boot 项目
而在Spring Boot中,其实已经帮你实现好了一个shutdownHook,支持响应Ctrl+c或者kill -15 TERM信号。
1 | public void registerShutdownHook() { |
在容器初始化时,ApplicationContext 便已经注册了一个 Shutdown Hook,这个钩子调用了 Close()方法,于是当我们执行 kill -15 pid 时,JVM 接收到关闭指令,触发了这个 Shutdown Hook,进而由 Close() 方法去处理一些善后手段。具体的善后手段有哪些,则完全依赖于 ApplicationContext 的 doClose() 逻辑,包括了注释中提及的销毁缓存单例对象,发布 close 事件,关闭应用上下文等等,特别的,当 ApplicationContext 的实现类是 AnnotationConfigEmbeddedWebApplicationContext 时,还会处理一些 tomcat/jetty 一类内置应用服务器关闭的逻辑。
我们能对它做些什么呢,其实很明显,在doClose方法中它发布了一个ContextClosedEvent的方法,不就是给我们扩展用的么。于是我们可以写个监听器监听ContextClosedEvent,在发生事件的时候做下线逻辑,对微服务来说即是从注册中心中注销掉服务。
1 |
|
微服务中一般来说,注销服务往往是优雅下线的第一步,接着才会执行停机操作,那么这个时候流量进来怎么办呢?
在注销服务之后就可开启请求挡板拒绝流量了,通过微服务框架(dubbo)本身的故障转移功能去处理被拒绝的流量即可
对于docker stop来说,它会发一个SIGTERM(kill -15 term信息)给容器的PID1进程,并且默认会等待10s,再发送一个SIGKILL(kill -9信息)给PID1。
那么很明显,docker stop允许程序有个默认10s的反应时间去做一下优雅停机的操作,程序只要能对kill -15 信号做些反应就好了,如上一步描述。那么这是比较良好的方式。
当然如果shutdownHook方法执行了个50s,那肯定不优雅了。可以通过docker stop -t 加上等待时间。
Spring Boot graceful shutdown
Graceful shutdown is supported with all four embedded web servers (Jetty, Reactor Netty, Tomcat, and Undertow) and with both reactive and Servlet-based web applications. When enabled using server.shutdown=graceful, upon shutdown, the web server will no longer permit new requests and will wait for a grace period for active requests to complete. The grace period can be configured using spring.lifecycle.timeout-per-shutdown-phase. Please see the reference documentation for further details.
Spring Boot 2.3.0.RELEASE引入了Graceful Shutdown的功能。其中应用在等待下线期间对待新请求的方式,取决于我们所使用的 Server 类型。根据官方文档Tomcat、Jetty 和 Reactor Netty将会在网络层面停止接收新的请求。Undertow 会继续接收新的请求,但立即会以 HTTP 503(服务不可用)来响应。
配置与使用
在Spring Boot 2.3.0中,优雅停机的使用非常简单,可以通过在应用程序配置文件中设置两个属性来进行。
1、 server.shutdown 属性可以支持的值有两种
- immediate 这是默认值,配置后服务器立即关闭,无优雅停机逻辑。
- graceful 开启优雅停机功能,并遵守 spring.lifecycle.timeout-per-shutdown-phase 属性中给出的超时来作为服务端等待的最大时间。
2、spring.lifecycle.timeout-per-shutdown-phase 服务端等待最大超时时间,采用java.time.Duration格式的值,默认30s。
例如:Properties 文件
1、#To enable graceful shutdown
2、server.shutdown=graceful
3、#To configure the timeout period
4、spring.lifecycle.timeout-per-shutdown-phase=20s
当我们使用了如上配置开启了优雅停机功能,当我们通过SIGTERM信号关闭 Spring Boot 应用时
1、 此时如果应用中没有正在进行的请求,应用程序将会直接关闭,而无需等待超时时间结束后才关闭。
2、 此时如果应用中有正在处理的请求,则应用程序将等待超时时间结束后才会关闭。如果应用在超时时间之后仍然有未处理完的请求,应用程序将抛出异常并继续强制关闭。
这里注意下,Tomcat 9.0.33或更高版本,才具备graceful shutdown功能。
springboot 更优雅点的方式
spring-boot-starter-actuator 模块提供了一个 restful 接口,用于优雅停机。
添加依赖
1 | <dependency> |
添加配置
1 | #启用 shutdown |
生产中请注意该端口需要设置权限,如配合 spring-security 使用。
执行 curl -X POST host:port/shutdown 指令,关闭成功便可以获得如下的返回:
1 | {"message":"Shutting down, bye..."} |
虽然 springboot 提供了这样的方式,但按我目前的了解,没见到有人用这种方式停机
kill -15 pid 的方式达到的效果与此相同,将其列于此处只是为了方案的完整性
如何销毁作为成员变量的线程池?
1 |
|
我们需要想办法在应用关闭时(JVM 关闭,容器停止运行),关闭线程池。
初始方案:什么都不做。在一般情况下,这不会有什么大问题,因为 JVM 关闭,会释放之,但显然没有做到本文一直在强调的两个字,没错 —- 优雅。
方法一的弊端在于线程池中提交的任务以及阻塞队列中未执行的任务变得极其不可控,接收到停机指令后是立刻退出?还是等待任务执行完成?抑或是等待一定时间任务还没执行完成则关闭
参考 spring 中线程池的回收策略
1 |
|
1 通过 waitForTasksToCompleteOnShutdown 标志来控制是想立刻终止所有任务,还是等待任务执行完成后退出。
2 executor.awaitTermination(this.awaitTerminationSeconds, TimeUnit.SECONDS)); 控制等待的时间,防止任务无限期的运行(前面已经强调过了,即使是 shutdownNow 也不能保证线程一定停止运行)
依赖中间件能力
dubbo
Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果用户使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才会执行.
服务提供方
- 停止时,先标记为不接收新请求,新请求过来时直接报错,让客户端重试其它机器。
- 然后,检测线程池中的线程是否正在运行,如果有,等待所有线程执行完成,除非超时,则强制关闭。
服务消费方
- 停止时,不再发起新的调用请求,所有新的调用在客户端即报错。
- 然后,检测有没有请求的响应还没有返回,等待响应返回,除非超时,则强制关闭。
设置方式
设置优雅停机超时时间,缺省超时时间是 10 秒,如果超时则强制关闭。
1 | # dubbo.properties |
如果 ShutdownHook 不能生效,可以自行调用:
1 | DubboShutdownHook.destroyAll(); |
建议
使用 tomcat 等容器部署的场景,建议通过扩展 ContextListener 等自行调用以下代码实现优雅停机
除了 现有部署方式 java -server java - client
dubbo server 项目 是否一定要使用 starter-web 那一套?
这实际上与HotSpot和默认选项值(Java HotSpot VM Options)链接在一起,这些默认值在客户端和服务器配置之间有所不同。
从白皮书的第2章(Java HotSpot性能引擎体系结构)开始:
JDK包括两种VM:客户端产品和为服务器应用程序调整的VM。这两个解决方案共享Java HotSpot运行时环境代码库,但是使用不同的编译器,这些编译器适合于客户端和服务器的独特性能特性。这些差异包括编译内联策略和堆默认值。
尽管服务器VM和客户端VM相似,但已经对服务器VM进行了特殊调整,以最大程度地提高峰值运行速度。它用于执行长时间运行的服务器应用程序,这些应用程序需要比快速启动时间或较小的运行时内存占用更多的最快的运行速度。
客户端VM编译器可作为经典VM和早期JDK版本使用的即时(JIT)编译器的升级。Client VM为应用程序和小程序提供了改进的运行时性能。Java HotSpot客户端VM经过特别调整,以减少应用程序启动时间和内存占用,使其特别适合客户端环境。通常,客户端系统更适合GUI。
因此,真正的区别还在于编译器级别:
客户端VM编译器不会尝试执行由服务器VM中的编译器执行的许多更复杂的优化,但是作为交换,它需要更少的时间来分析和编译一段代码。这意味着客户端VM可以更快地启动,并且需要较小的内存空间。
Server VM包含一个高级自适应编译器,该编译器支持通过优化C ++编译器执行的许多相同类型的优化,以及一些传统编译器无法完成的优化,例如跨虚拟方法调用的主动内联。与静态编译器相比,这是一个竞争优势和性能优势。自适应优化技术的方法非常灵活,通常甚至优于高级静态分析和编译技术。
配置 dubbo.properties
1 | =15000 |
已集成 apollo 的项目.
arch-common 公共 namespace 配置即可
发起 http /telnet 调用 均可
parent POM 配置
优雅上线
1.initializr生成代码的时候,添加配置,不将服务暴露出来
1 | <dubbo:service register="false" /> |
2.oms在服务启动的时候去做健康监测,发现健康监测成功后,执行QOS命令将服务暴露出去
1 | curl localhost:22222/online |
优雅下线
服务下线或pod缩容的时候,执行QOS命令并等待${time_out}S,才真正将pod关闭
1 | curl localhost:22222/offline |
dubbo 调用失败时. ( 幂等性)
集群调用失败时,Dubbo 提供的容错方案
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
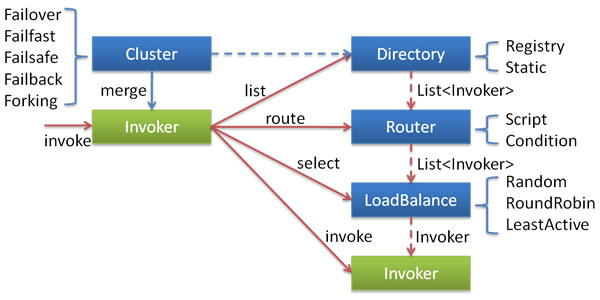
各节点关系:
- 这里的
Invoker是Provider的一个可调用Service的抽象,Invoker封装了Provider地址及Service接口信息 Directory代表多个Invoker,可以把它看成List<Invoker>,但与List不同的是,它的值可能是动态变化的,比如注册中心推送变更Cluster将Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Router负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选
集群容错模式
可以自行扩展集群容错策略,参见:集群扩展
Failover Cluster
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
重试次数配置如下:
1 | <dubbo:service retries="2" /> |
或
1 | <dubbo:reference retries="2" /> |
或
1 | <dubbo:reference> |
提示
该配置为缺省配置
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
提示
2.1.0 开始支持
集群模式配置
按照以下示例在服务提供方和消费方配置集群模式
1 | <dubbo:service cluster="failsafe" /> |
或
1 | <dubbo:reference cluster="failsafe" /> |
artemis
依靠 ACK 机制 + 消息持久化
3接入artemis 场景 ,业务方已知 client端消费幂等性处理 , server 三次 推送 3次推送, consumer 幂等消费
服务端分片均匀推送
eg: 普通kafka 12 个pod ,三个分片, 只有 abc 能收到, artemis 均匀分配负载均衡 ,每4 个pod 通过dubbo直连 拉取 一个分片
推进业务方接入 artemis 即可
elasticjob
定时任务较多的服务,处理下线则特别需要注意优雅停机的问题,因为这是一个长时间运行的服务,比其他情况更容易受停机问题的影响,可以使用幂等和标志位的方式来设计定时任务
client 端配置
task 配置 分片配置. 分片数多为1 , client 端 execute() 未做幂等处理

1 job task dashboard 完善 加上 cost time ,过往执行任务 耗时cost time dashboard 过往经验 辅助分析 ,实际task cost time
2 cron 表达式, 周期语义翻译

server 端自身的下线
delay queue
client 端 pod 下线
大致流程:
可以在 jvm 注册一个 Runtime.getRuntime().addShutdownHook(Runnable)停机回调接口
关闭所有的topic监听线程
关闭重试线程
异常未消费Job重入 进行重试机制
server端自身 的下线 待确认
中间件应用服务自身的优雅上下线
dubbo服务的server 大部分可沿用,待评估
media center 部分模块未容器化部署 ,file upload
目前有调用 FFmpeg 音频转码操作, 线程wait 一定时长 ,
会对已在执行转码的进程 评估最终kill -9 的default timeout 时间 有一定影响, 待评估
elasticjob
cat 未容器化
alert-server
已做服务自省能力
监控告警能力
在执行应用的优雅下线.
关注此次操作时间点+ period 时间段内 有无业务中断的报错 dashboard alert push
业务实践场景流程
k8s体系下 微服务优雅上下线
kubernetes滚动升级的过程
- 集群Deployment 或者 Statefulset 发生变化,触发部署滚动升级;
- 根据 Deolyement 等配置,K8S集群首先启动新的POD来替代老 POD;
- Deployemnt 根据配置调度 POD,拉取镜像,此时 POD 进入 Pending 状态;
- POD 绑定到Node上,启动容器,在就绪检查readinessProbe 探针通过后,新的POD进入Ready状态;
- K8S集群创建Endpoint,将新的POD纳入Service 的负载均衡;
- K8S集群移除与老POD相关的Endpoint,并且将老POD状态设置为Terminating,此时将不会有新的请求到达老POD,同时调用PreStop Hook执行配置的脚本;
- K8S集群会给老POD发送SIGTERM信号,并且等待 terminationGracePeriodSeconds 这么长的时间。(默认为30秒,可以根据优雅下线服务需要消耗时间调整)
- 超过terminationGracePeriodSeconds等待时间后, K8S集群会强制结束老POD,在这个时间段内要将老 POD 资源释放掉,否则可能残留无用资源被占用。
从以上过程可以看到,如果在terminationGracePeriodSeconds 没有及时释放服务注册等资源信息,Service 负载均衡的健康检查又没有检查到老 POD服务已经挂掉,导致请求分发到这些 POD 上,从而触发一系列的请求错误,因而需要配置优雅下线脚本,在terminationGracePeriodSeconds 时间段内执行完毕。
公有云方案 EDAS

如图看到,我们通过3个步骤的增强,主动注销、服务提供者通知下线信息、服务消费者调用其他服务提供者。
可以看到,真正做到无损下线能力是需要客户端增强一起联动的
• 主动注销
我们在应用服务下线前,主动通知注册中心注销该实例
• 通知下线信息
我们会在服务端实例下线前主动通知客户端,该服务节点下线的信息
• 调用其他提供者
我们在客户端增强其负载均衡能力,在服务端下线后,客户端主动调用其他服务提供者节点
同时我们提供应用等待的逻辑,使要下线的服务端等待已经收到的请求处理完成再关闭 Spring 容器。

EDAS 3.0支持端到端的无损下线
- 云上客户存在多种微服务网关,支持主流开源微服务网关(Spring Cloud Gateway、Zuul等)的无损下线
- 有些用户的流量是通过 Ingress、SLB、Nginx 等方式打到服务端的场景
- MQ消息等异步订阅关系的微服务场景
- K8s 使用 Service 服务发现的微服务场景
为了做到全链路的无损下线,EDAS 3.0 通过无侵入的方式涵盖多种场景的完整解决方案,确保您的发布平滑无损。
优雅启动
kubernetes 集群提供了探针,类似健康检查,只有该请求通过,新的 POD 才能进入 Ready 状态,kubernetes集群才会将新的 POD 纳入 Service 的负载均衡。
因而如果该应用(POD)仅仅提供 service 配置的服务,不需要配置探针,就可以优雅启动,但是实际 POD 往往还有 HSF,LWP,Dubbo等注册于配置服务其实现负载均衡的服务,所以需要确保这些服务都已经启动,所以需要配置相应的探针。
同时,任何一个服务可能在运行中因为某种原因不稳定,导致服务中断,这个时候还需要配置livenessProbe探针,确保服务出故障时及时止损。
我们的应用主要有HSF,LWP 和 Https 服务,对于三种服务都有的应用,要求应用提供健康检查的接口,能即时检查三种服务都正常与否,然后做以下配置:
1 | livenessProbe: |
readinessProbe配置表示只有5804端口请求正常返回,pod 才会进入 ready 状态,确保各种服务 ok 。
livenessProbe 表示每10s 探一下5804端口,如果返回失败,达到阈值后,pod 会重启,对于服务出问题的 POD 及时止损。
注意:readinessProbe探针的 探测频率和延时时间,不健康阈值等数据要合理,部分应用启动时间本身较长,如果设置的时间过短,会导致 POD 反复无效重启
优雅下线
我们的应用云上主要有 HSF,LWP 和 Https 服务,在 pod prestop里设置执行摘除服务注册信息脚本,来完成优雅下线。
https 服务基于 kubernetes 服务 Service 来实现服务暴露,在老 POD 状态设置为Terminating后,就不会有请求达到,因而已经优雅下线;
lwp 服务,通过注册 vipserver 来提供负载均衡,需要在下线前先摘除该服务注册,防止 老POD 下线后还有请求达到老 POD;
HSF 服务通过注册 configserver 来提供负载均衡,需要在下线前先摘除该服务注册,防止 老POD 下线后还有请求达到老 POD。
yaml:
1 | lifecycle: |
preStop在 pod 终止之前,执行脚本 appctl.sh {app_name} stop
终止 HSF 与 LWP 脚本:
1 | !/bin/bash |
系统对接细节
k8s机制细节
Kubernetes 中针对应用的的管控提供了丰富的手段,正常的情况它提供了应用生命周期中的灵活扩展点,同时也支持自己扩展它的 Operator 自定义上下线的流程
一个 Kubernetes 应用实例下线之前,管控程序会向 POD 发送一个 SIGTERM 的信号,应用响应时除了额外响应这一个信号之外,还能触发一段自定义的 PreStop 的挂在脚本,代码样例如下
应用healthcheck机制
Kubernetes 会根据健康检查的情况来更新服务(Service)列表,其中如果 Liveness 失败,则会触发容器重建,这是一个相对很重的操作;若 Readiness 失败,则 Kubenetes 则默认不会将路由服务流量到相应的容器
Spring Boot 内置了相应的 API、事件、Health Check 监控
1 | java |
EP效能 发布系统
oms运维系统 发布模块
VM发布
容器应用发布
系统对接
提供spring /springboot 层面sdk 处理停机上线event
优雅下线前置检查条件,soa-platform 提供
发布系统(oms )通知中间能力优雅下线/上线
pod preStop 执行的shell脚本
发起pod优雅下线事件event mq
apollo可配置 应用停机默认 timeout
系统交互设计参考
https://cloud.tencent.com/developer/article/1509124
未来可能演进
云原生微服务架构
quarkus
Dubbo 3.0 对接 Kubernetes
拥抱 service mesh
在 Kubernetes 集群中,Dubbo 应用的部署方式往往需要借助第三方注册中心实现服务发现。Dubbo 与 Kubernetes 的调度体系的结合,可以让原本需要管理两套平台的运维成本大大减低,而且 Dubbo 适配了 Kubernetes 原生服务也可以让框架本身更加融入云原生体系。基于 Dubbo 3.0 的全新应用级服务发现模型可以更容易对齐 Kubernetes 的服务模型
待确认问题
1 healthcheck 点火机制 ,频次 1.5~2s/次
2 中间件,公共服务自身的特殊场景梳理
3 测试方案
4 dubbo 是否需要healthcheck